【说明】
在Windows操作系统下,wchar_t的大小是两个字节,其默认的编码方式是UTF-16(Unicode的一种存储方式)。其中,每个基本多语言平面字符占据两个字节,也就是一个wchar_t数组元素;每个辅助平面字符占据四个字节,即两个wchar_t数组元素。例如,字符“长”是基本多语言平面字符,而“卒瓦”这两个字合在一起的那个汉字就是一个辅助平面字符(这个字符目前在Arslanbar还无法发表)。注意,如果用wcslen函数测定wchar_t字符数组的长度,数组中的每个辅助字符将会被认为是两个字符。
为了能让文本编辑器识别写入的txt文件是UTF-16编码格式,必须在文件开头写入两个字节的BOM作为标记(对于UTF8则是三个字节的BOM,不过这个BOM是可写可不写的)。UTF-16分为大尾序和小尾序两种格式,其BOM分别是0xFEFF和0xFFFE。在Windows和Linux系统上一般使用小尾序,而在Mac系统上则一般使用大尾序。在C++中我们可以用一个char字符数组存储这个BOM,然后写入txt文件的开头。
【代码】
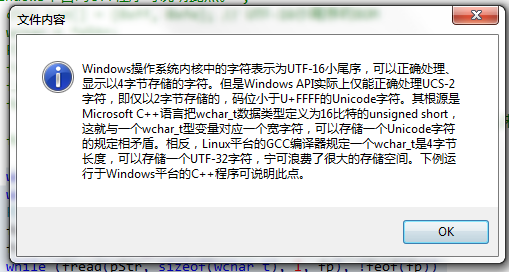
wchar_t wstr[] = L"Windows操作系统内核中的字符表示为UTF-16小尾序,可以正确处理、显示以4字节存储的字符。但是Windows API实际上仅能正确处理UCS-2字符,即仅以2字节存储的,码位小于U+FFFF的Unicode字符。其根源是Microsoft C++语言把wchar_t数据类型定义为16比特的unsigned short,这就与一个wchar_t型变量对应一个宽字符,可以存储一个Unicode字符的规定相矛盾。相反,Linux平台的GCC编译器规定一个wchar_t是4字节长度,可以存储一个UTF-32字符,宁可浪费了很大的存储空间。下例运行于Windows平台的C++程序可说明此点。";
char bom[] = {0xff, 0xfe}; // UTF-16小尾序的BOM
wchar_t *pStr;
FILE *fp;
fopen_s(&fp, "utf16.txt", "wb"); // 打开文件
fwrite(bom, sizeof(bom), 1, fp); // 在文件头部写入BOM
for (pStr = wstr; *pStr != '\0'; pStr++)
fwrite(pStr, sizeof(wchar_t), 1, fp); // 写入字符串,不写入末尾的\0
fclose(fp); // 关闭文件
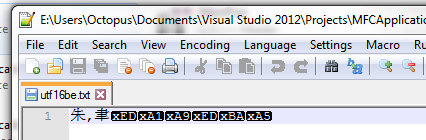
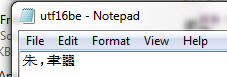
【运行结果】